Interactive Q learning
The best way to learn about Q tables…
 Give me maximum reward :)
Give me maximum reward :)
Go play @ Interactive Q learning
Code @ Mohit’s Github
Introduction
While going through the process of understanding Q learning, I was always fascinated by the grid world (the 2D world made of boxes, where agent moves from one box to another and collect rewards). Almost all of the courses in Reinforcement learning begins with a basic introduction to Q tables and the most intuitive Q tables examples are of grid worlds. That said, many courses only draw their static worlds and provide no playing material to the audience. To counter this, I thought of creating an interactive grid world, where user can define the world, states and agent. This will help user replicate the course’s grid world and understand how it really works and even question — what happens when you change the fixed variables? Let’s get started!
Interactive Grid World
 Interactive grid worldThe interactive grid world is divided into two main areas,
Interactive grid worldThe interactive grid world is divided into two main areas,
- Playground: Consists of boxes or states, where the action takes place.
- Settings: Consists of multiple levels of settings by which you design and control the playground. Let’s try to understand the dynamics of the grid world by going through the available settings. The settings area can be further divided into,
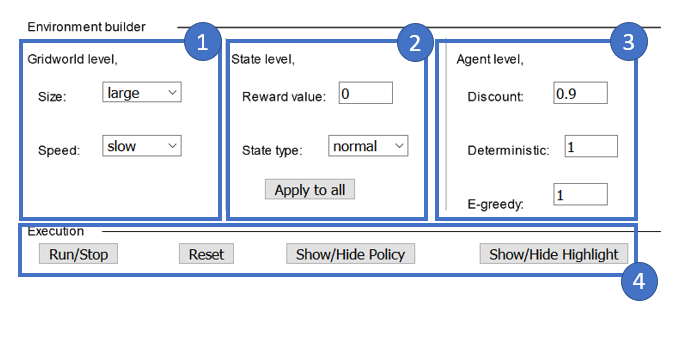
As shown above, the 4 subsections of settings are,
-
Gridworld level settings: Consists of settings which change the format of the overall world, contains
— Size: Select the size of the world. “Large” means more number of states.
— Speed: Select the speed of processing. “Fast” is good when we want to get final result quick but “slow” is best for intuitive visualization.
-
State level settings: Helps in designing the individual states and their behavior, contains
— Reward value: The reward assigned to clicked state.
— State type: The types of state. ‘Terminal’ — basically the game over state, agent completes the current episode when it enters a terminal state. ‘Wall’ — a fixed state with no reward, one agent can’t cross. ‘Normal’ — the default state type.
— Apply to all: Shortcut button to apply the current reward value and state type to all of the boxes in the grid world.
-
Agent level settings: Defines the agent’s learning behavior, contains
— Discount: The discount applied to future rewards. The default value is 0.9.
— Deterministic: Defines the deterministic probability of the agent’s actions. 1 means a “right” from a box will always lead to the box on right. Whereas 0.7 means there is only a 70% chance for this to happen and a 10% chance of going to any of the adjacent states. (For math geeks, 3 remaining adjacent states, hence 10 * 3 = 30 % which completes the 100%)
— E-greedy: Defines the exploit/explore nature of the agent. 0 means the agent is completely greedy and will always select the best action available. 1 means the agent is completely random and could select from any available actions. To understand more about epsilon-greedy, I would suggest going through my earlier post, Reinforcement learning with multi-arm bandit.
-
Execution type settings: Controls the flow of the world, contains
— Run/Stop: Let the agent play inside the gridworld. Toggles the switch.
— Reset: Go back to the initial settings and dynamics.
— Show/Hide policy: Toggle the visibility of policy direction arrows.
— Show/Hide Highlight: Toggle the visibility of the current state’s highlight.
How to play?
Let take some examples to understand this better.
Example 1: The first example could be “The Beer Game” from my earlier post about reinforcement learning with Q tables. I would suggest going through the post to get a basic idea about the Q tables. So the world looks like this,
 The beer gameAnd we want the agent to learn to always go to the state with beer rather than the one with a hole. Let’s recreate this in our interactive grid world,
The beer gameAnd we want the agent to learn to always go to the state with beer rather than the one with a hole. Let’s recreate this in our interactive grid world,
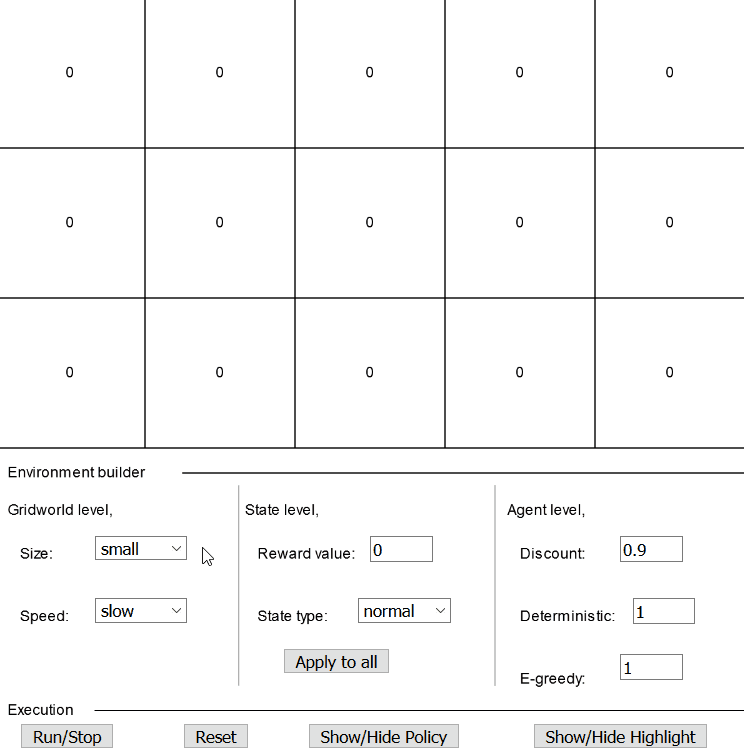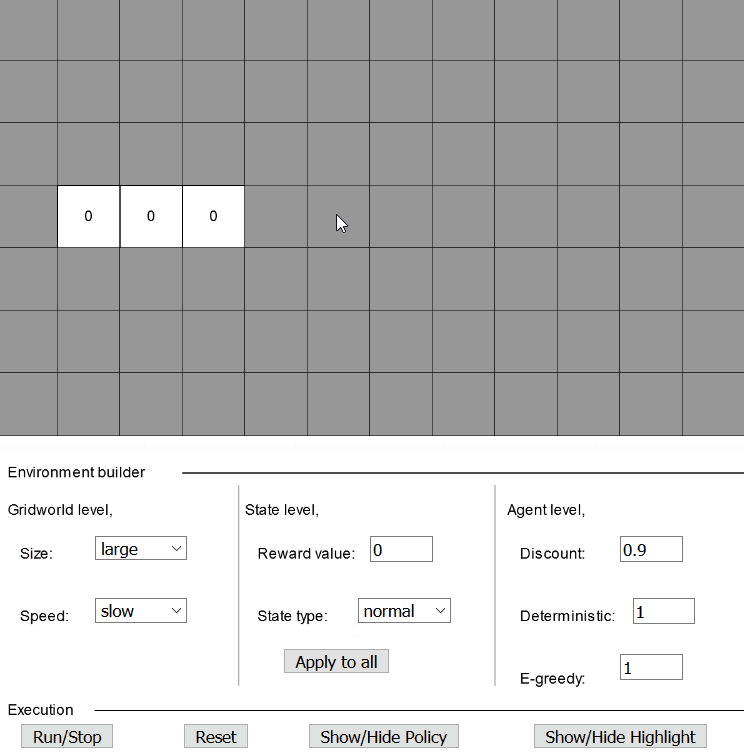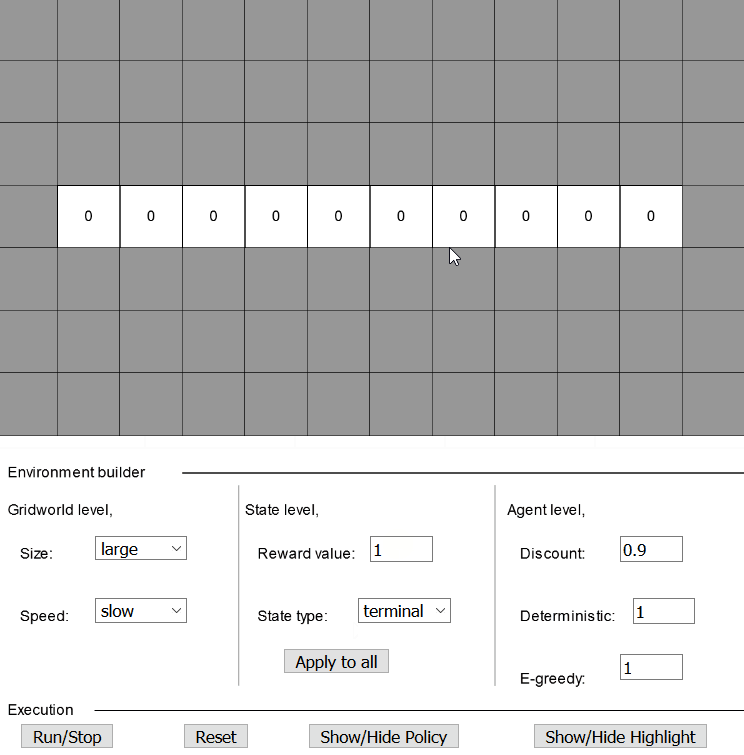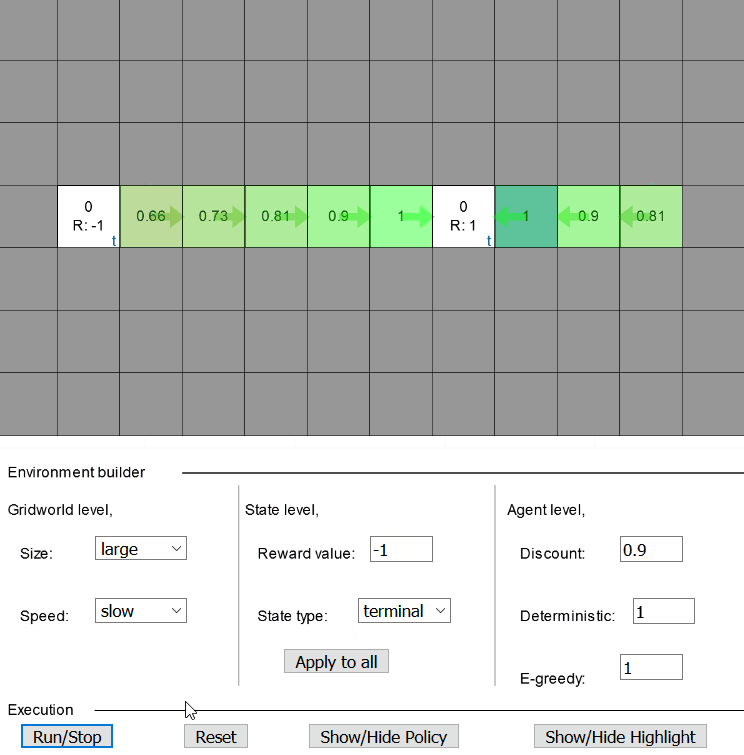 Solving example 1 on interactive grid worldFinally, the grid world looks like this,
Solving example 1 on interactive grid worldFinally, the grid world looks like this,
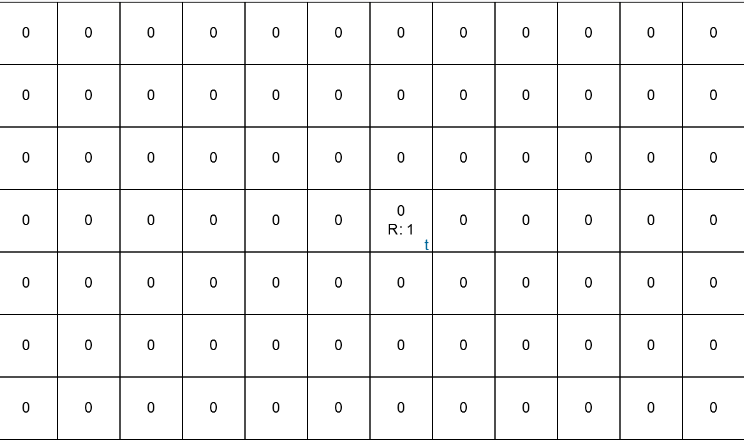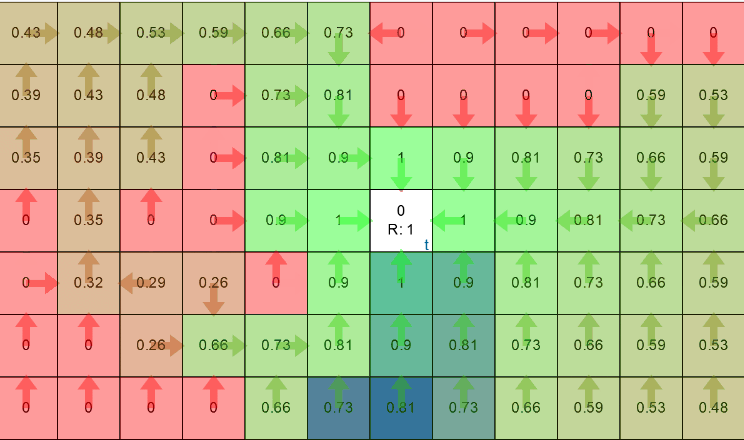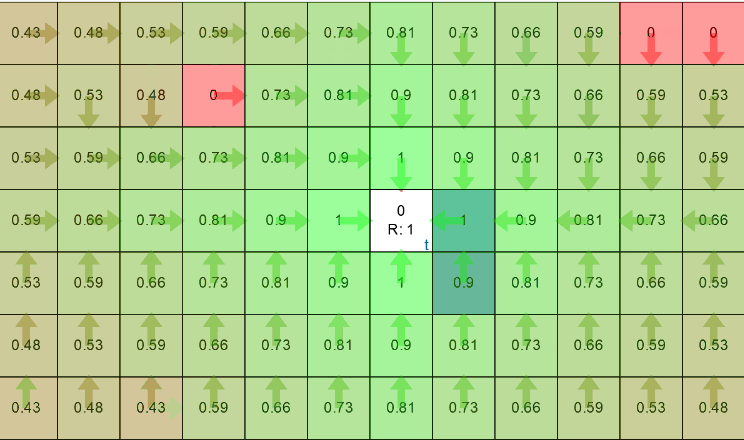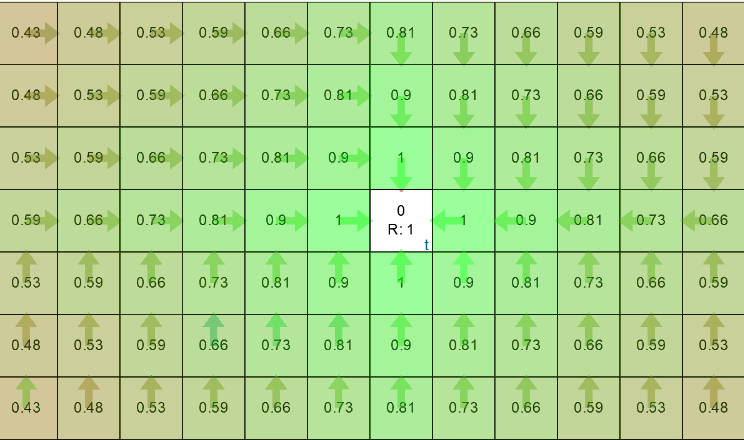
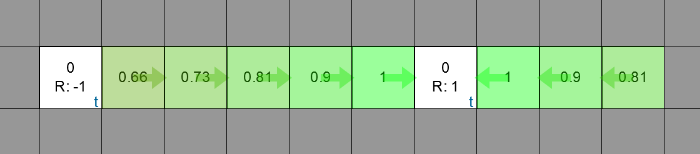 Agent’s expected rewards and policy after convergence for example 1.Example 2: Let’s take one example from Udemy’s Artificial intelligence course. The world looks like this,
Agent’s expected rewards and policy after convergence for example 1.Example 2: Let’s take one example from Udemy’s Artificial intelligence course. The world looks like this,
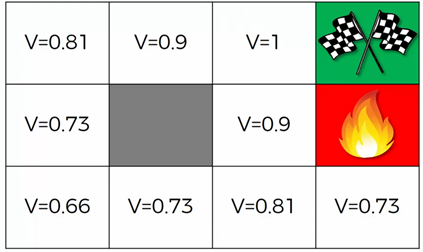 Green flags have reward of 1 and the state with fire has negative reward, say -1.
Green flags have reward of 1 and the state with fire has negative reward, say -1.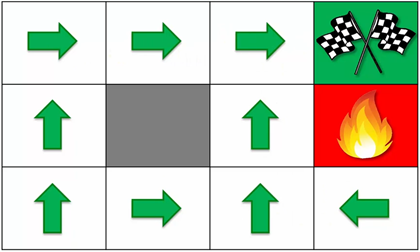 The policy learned after convergence.The expected state reward (V) in the above image along with the directions (policy) are learned after going through multiple iterations of training. Let’s try to replicate this world as well,
The policy learned after convergence.The expected state reward (V) in the above image along with the directions (policy) are learned after going through multiple iterations of training. Let’s try to replicate this world as well,
 Solving example 2 on interactive grid worldFinally the grid world looks like this,
Solving example 2 on interactive grid worldFinally the grid world looks like this,
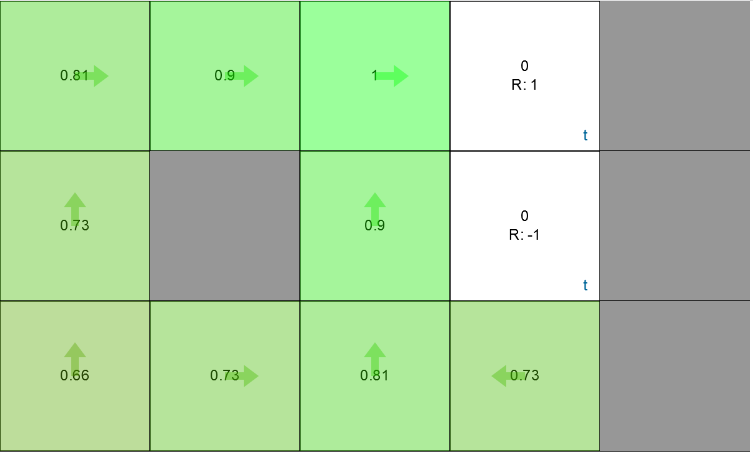 Agent’s expected rewards and policy after convergenceCompare this with the one shown in the course’s slides, its exactly the same!
Agent’s expected rewards and policy after convergenceCompare this with the one shown in the course’s slides, its exactly the same!
Conclusion
The project is far from over! There are many things that I want to add to this, but I guess they will come with time. The current version may have some bugs, hence in case of any unwanted behavior please resort to the final options — refresh the page and report issue at GitHub :) Other than that, please go ahead give it a try.
References
[1] Udemy’s Artificial Intelligence A-Z™: Learn How To Build An AI
[2] UC Berkeley CS188 Intro to AI
[3] Reinforce.js by Andrej Karpathy
Cheers!