Introduction to Genetic Algorithm
Getting one step closer to the evolutionary biological process, to infer how the natural phenomenon can be employed to solve complex computer science problems.

Introduction
Before we get started, we need to understand what’s really genetic about the genetic algorithm. Based on the phenomenon of natural selection and evolution, genetic algorithm tries to leverage the process of genetic crossover, mutation, among others, to highly optimize the process of the evolution, in computer science’s case the process of convergence to a problem’s solution.
The flow
The step-wise process of genetic algorithm is highly influence by the natural evolution. It goes through a sequence of events, each dependent on the previous one for its success, to replenish an older population with a newer and hopefully better one. Here, better means entities of newer population having better DNA. Now the exact definition of population, its entities and their DNA, is quite vague and depends on the problem in hand. The steps are,
- **Initialization: **The first step which involves creating the first population, defining its size, contained entities, the fitness parameters, etc. Think of this as more of a pre-processing step before the real magic begins.
- **Fitness calculation: **This entails calculating the fitness of each entity. Now fitness is basically a score which defines how closer the current entity is to required final/perfect one, the closer it is higher its score is.
- Selection: Here we select the entities from our population who are given permission for reproduction. A perfect elitism would require selecting only the best one, a more realistic method would be leaving the selection matter in hands of randomness, alas with a little bias towards the entities with better fitness score.
- Crossover: Here the selected entities breed to produce their offspring and the most important matter is how do we combine the parent’s DNA to create child’s DNA.
- Mutation: A child is not always the perfect copy of their parents, and sometimes even show behavior not present in either of them. Here we try to formulate the probability of mutation and how does it affects the child’s DNA.
The problem
To better understand and appreciate the logic, lets take one example problem and try to solve it with genetic algorithm. How about teaching an agent to guess a password. Now we will try to make it little bit fair for the agent, and for each guess, we provide a score of its correctness, which could be nothing but the number of letters the agent got right. The password could of any length and for simplicity we only use English alphabets and spaces. Now why is this problem hard? There are 26 letters in English alphabets, considering the upper and lower cases, we get 52, throw in space (blank character) and we have 53 possible characters for a position. And lets say the password was “The pen is mightier than the sword” we have 53 letters contending for 34 positions (length of the phrase). That’s 53 * 53 * 53…. a total of 34 times, which equals to more than 42 octadecillion different combinations (just google it to see how big that number is, hint: has 58 zeros). Now imagine someone randomly trying to guess it. Even the fastest super computers will take years (more than the life of the our universe) to solve it. To begin with we can select smaller passwords, but the problem remains, exponential growth in complexity with each increase in character.
Step 1: Initialization
Here we define the population, lets say it’s the number of possible current guesses for the password, which makes each such guess one entity. Now the DNA of the entity (guess) will be the guessed password, in our case a N length sequence of characters. Lets code it away,
class Population:
def __init__(self, pop_size, dna_size, target, mutate_prob = 0.01):
self.pop_size = pop_size
self.dna_size = dna_size
self.entities = [Entity(dna_size) for x in range(pop_size)]
self.mutate_prob = mutate_prob
self.target = targetclass Entity:
def __init__(self, dna_size = None, dna = None):
self.dna_size = dna_size
if dna:
self.dna = dna
self.dna_size = len(dna)
else:
self.dna = choose_random_alphabets(dna_size)
self.fitness = 0.01
def __str__(self):
return ““.join(self.dna)def choose_random_alphabets(size):
relevant_characters = string.ascii_letters + ‘ ‘
return random.sample(relevant_characters, size)Also lets initialize the population of size 150, and for starters each entity will be random sequence of characters,
target = “aeiou”
pop = Population(150, len(target), list(target))#### Step 2: Fitness calculation
What should be the fitness of a password? Obviously the number of correct characters at correct positions. So for each guess, we will compare it character by character and count off the number of times we find similar character. Finally dividing the with the length of the password, we have a bounded score of similarity which is the score or fitness of the selected guess. (add these to Entity class)
def calculate_fitness(self, target):
self.fitness = max(self.compare(target), 0.01)def compare(self, another_dna_value):
matched_count = 0
for x,y in zip(self.dna, another_dna_value):
if x == y:
matched_count += 1
return matched_count/self.dna_size#### Step 3: Selection
We have a population of guesses, and we know their fitness, now we need to identify the interesting candidates which are eligible for passing their information to the next generation of guesses. One tried and tested way is to provide a probability of importance of a guess based on its fitness score i.e. higher the fitness score of a guess, better its chances to get selected. To do so we normalize every entities’ fitness by dividing it with the sum of all fitness values. This gives us the probability of importance of each entity. Now we just have to enforce the logic of this importance, this could be done by, (add these to Population class)
def create_mating_pool(self):
# calculate the fitness
ttl_fitness = 0
for x in self.entities:
x.calculate_fitness(self.target)
ttl_fitness += x.fitness
# normalize the fitness
normalized_fitness = []
entities = []
for x in self.entities:
x.fitness = x.fitness/ttl_fitness
normalized_fitness.append(x.fitness)
entities.append(x)
# create a mating pool
for x in range(self.pop_size):
yield np.random.choice(entities, 2, p = normalized_fitness)#### Step 4: Crossover
On reaching this part, we get pairs of parent (older population of guesses) and we try to formulate how to pass on their information (their password characters) to children (newer population). Lets go with a simple logic of single point crossover, which says, one half of the child’s DNA comes from separate parents. Now this half could have literal meaning by being the midpoint of the DNA or we can randomly choose a point of cut. Going with the latter logic, we have, (add these to Population class)
def crossover_random_single_point(self, first_parent, second_parent):
# get random index
index = np.random.choice(len(first_parent.dna), 1)[0]
# crossover by the index
part_one = first_parent.dna[:index]
part_two = second_parent.dna[index:]
# combine
part_one.extend(part_two)
modified_gene_value = part_one
# return
return modified_gene_value#### Step 5: Mutation
Ever heard of brown eyed parents giving birth to blue eyed baby? Or animals developing newer organs to survive in new environment? Well all are classic example of mutation where modification in some genes of the DNA takes place. In our case, we randomly go through each character (gene) of the child’s guessed password (DNA) and based on a probability, query if we need to modify (mutate) this character or not. If no, we move on, if yes we replace it with another random character. Usually we keep this rate of mutation low otherwise it will overshadow the progress of evolution. (add these to Population class)
def breed(self):
# till we have populated same size
new_population = []
for first_parent, second_parent in self.create_mating_pool():
# crossover logic
modified_gene_value = self.crossover_random_single_point(first_parent, second_parent)
# mutate; if you are unlucky…or lucky?
for index in range(len(modified_gene_value)):
# check if mutate probability is satisfied
if np.random.random() <= self.mutate_prob:
modified_gene_value[index] = choose_random_alphabets(1)[0]
# create new entity with the parent’s combined genes
new_population.append(Entity(dna = modified_gene_value))
# when done replace the population
self.entities = list(new_population)#### Solution
Joining the pieces together and re-iterating the steps for some generations, lets see how long it takes for our population to correctly guess the different passwords.
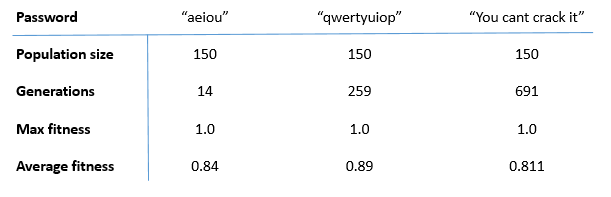 Genetic algorithm to solve the password cracking problem.For each individual password, let’s also plot the progress graph of average fitness of population over the generations.
Genetic algorithm to solve the password cracking problem.For each individual password, let’s also plot the progress graph of average fitness of population over the generations.
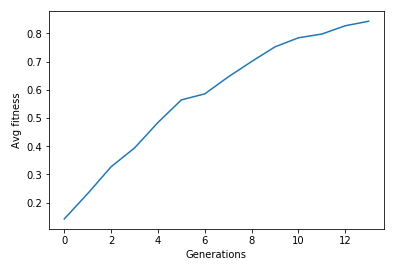 password: “aeiou”
password: “aeiou”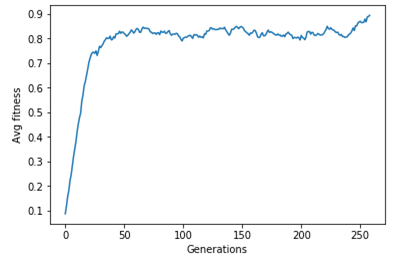 password: “qwertyuiop”
password: “qwertyuiop”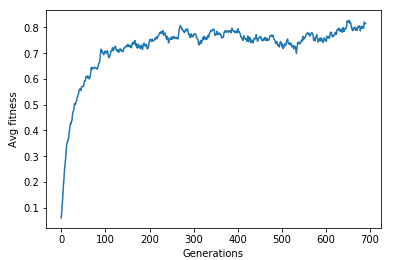 password: “You cant crack it”One thing is evident, as the generation increases the fitness of the population increases. Sure there are some oscillations due to mutation, but on the larger picture the population evolves with newer entities and with it our chance of finding a better solution.
password: “You cant crack it”One thing is evident, as the generation increases the fitness of the population increases. Sure there are some oscillations due to mutation, but on the larger picture the population evolves with newer entities and with it our chance of finding a better solution.
Conclusion
We took a classic example of password cracking, genetic algorithms can be used for a variety of problems where we have somewhat little notion of fitness. Some broad examples could be traveling salesman, function optimization, multi-object optimization, game playing agents, etc. Also we kept numerous parameters fixed, like the mutation rate, the population size, the fitness scores, also intensive research have been done on the effect of choosing different logic for crossover, mutation and selection. It will be interesting to see the effect on our solution due to these variations. Well maybe in another post.
Cheers.