Reinforcement Learning with Multi Arm Bandit
This is Part 1 of two part articles. The combined article is present in the Lazy Data Science Guide.
Lets talk about the classical reinforcement learning problem which paved the way for delayed reward learning with balance between exploration and exploitation.

Introduction
- The bandit problem deals with learning the best decision to make in a static or dynamic environment, without knowing the complete properties of the environment. It is like given a set of possible actions, select the series of actions which increases our overall expected gains, provided you have no prior knowledge of the reward distribution.
- Let’s understand this with an example, suppose you found a teleportation portal (Sci-fi fan anyone?), which opens up to either your home or middle of the ocean, where the either part is determined by some probability distribution. So if you step into the portal, there is some probability say
p, of coming out at your home and probability1-p, of coming out at the middle of the ocean (let’s add some sharks in the ocean :shark:). I don’t know about you guys, but I would like to go to the former. If we know, say that 60% of the time the portal leads to ocean, we would just never use it or if we land home 60% of the time, using portal might become a little more appealing. But what if we don’t have any such knowledge, what should we do? - Now, suppose we found multiple (
n) such portals, all with the same choices of destinations but different and unknown destination probability distribution. The n-armed or multi arm bandit is used to generalize this type of problems, where we are presented with multiple choices, with no prior knowledge of their true action rewards. In this article, we will try to find a solution to above problem, talk about different algorithms and find the one which could help us converge faster i.e. get as close to the true action reward distribution, with least number of tries.
!!! Hint The multi-armed bandit problem gets its name from a hypothetical scenario involving a gambler at a row of slot machines, sometimes known as “one-armed bandits” because of their traditional lever (“arm”) and their ability to leave the gambler penniless (like a robber, or “bandit”). In the classic formulation of the problem, each machine (or “arm”) provides a random reward from a probability distribution specific to that machine. The gambler’s objective is to maximize their total reward over a series of spins.
Exploration vs Exploitation
- Consider this scenario - Given
nportals, say we tried the portal #1, and it led to home. Great, but should we just consider it as the home portal and use it for all of our future journeys or we should wait and try it out a few more times? Let’s say, we tried it a few more times and now we can see 40% of the times it opens to home. Not happy with the results, we move on to portal #2, tried it a few times and it has 60% chance of home journey. Now again, should we stop or try out other portals too? Maybe portal #3 has higher chances of home journey or maybe not. This is the dilemma of exploration and exploitation. - The approach that favors exploitation, does so with logic of avoiding unnecessary loss when you have gained some knowledge about the reward distribution. Whereas approach of favoring exploration does so with logic of never getting biased with the action rewards distribution and keep trying every actions in order to get the true properties of the reward distribution.
- Ideally, we should follow a somewhat middle approach that explores to find more reward distribution and as well as exploits known reward distribution.
The Epsilon-Greedy algorithms
-
The greedy algorithm in reinforcement learning always selects the action with highest estimated action value. It’s a complete exploitation algorithm, which doesn’t care for exploration. It can be a smart approach if we have successfully estimated the action value to the expected action value i.e. if we know the true distribution, just select the best actions. But what if we are unsure about the estimation? The “epsilon” comes to the rescue.
-
The epsilon in the greedy algorithm adds exploration to the mix. So counter to previous logic of always selecting the best action, as per the estimated action value, now few times (with epsilon probability) select a random action for the sake of exploration and the remaining times behave as the original greedy algorithm and select the best known action.

- Hint: A 0-epsilon greedy algorithm with always select the best known action and 1-epsilon greedy algorithm will always select the actions at random.
Example - The Portal Game
Let’s understand the concept with an example. But before that here are some important terms,
- Environment: It is the container of agent, actions and reward; allows agent to take actions and assign rewards based on the action, following certain set of rules.
- Expected Action Value: Reward can be defined as objective outcome score or value of an action. In that sense the expected action value can be defined as the expected reward for the selected action i.e. the mean reward when an action is selected. This is the true action reward distribution.
- Estimated Action Value: This is nothing but the estimation of the Expected Action values which is bound to change after every learning iteration or episode. We start with an estimated action value, and try to bring it as close as possible to the true/expected action value. One way of doing it could be just taking the average of the rewards received for an action till now.
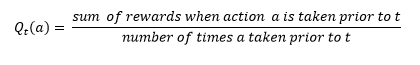
Say we have 10 portals with the expected action value for favorable home journey given as a uniform distribution,
import numpy as np
np.random.seed(123)
expected_action_value = np.random.uniform(0 ,1 , 10)
print(expected_action_value)
# Output ->
# array([0.69646919, 0.28613933, 0.22685145, 0.55131477, 0.71946897,
# 0.42310646, 0.9807642 , 0.68482974, 0.4809319 , 0.39211752])
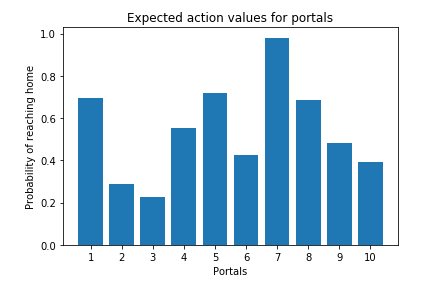
With knowledge of expected action value, we could say always choose portal #7; as it has the highest probability of reaching home. But as it is with the real world problems, most of the times, we are completely unfamiliar with the rewards of the actions. In that case we make an estimate of the reward distribution and update it as we learn. Another interesting topic of discussion could be strategy to select optimial initial estimate values, but for now lets keep it simple and define them as 0.
estimated_action_value = np.zeros(10)
estimated_action_value
# Output ->
# array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
Lets also define the reward function. Going by our requirement, we want to land at home, so lets set reward of value 1 for landing at home and -1 for landing in the ocean.
def reward_function(action_taken, expected_action_value):
if (np.random.uniform(0, 1) <= expected_action_value[action_taken]):
return 1
else:
return -1
Now lets define the bandit problem with estimate action value modification and epsilon-greedy action selection algorithm.
def multi_arm_bandit_problem(arms = 10, steps = 1000, e = 0.1, expected_action_value = []):
# Initialize lists to store rewards and whether the optimal actions for each step was taken or not
overall_reward, optimal_action = [], []
# Initialize an array to keep track of the estimated value of each action
estimate_action_value = np.zeros(arms)
# Initialize a count array to keep track of how many times each arm is pulled
count = np.zeros(arms)
# Loop for the given number of steps
for s in range(0, steps):
# Generate a random number to decide whether to explore or exploit
e_estimator = np.random.uniform(0, 1)
# If the random number is greater than epsilon, choose the best estimated action,
# otherwise, choose a random action
action = np.argmax(estimate_action_value) if e_estimator > e else np.random.choice(np.arange(10))
# Get the reward for the chosen action
reward = reward_function(action, expected_action_value)
# Update the estimated value of the chosen action using the incremental formula
estimate_action_value[action] = estimate_action_value[action] + (1/(count[action]+1)) * (reward - estimate_action_value[action])
# Record the received reward and whether the chosen action was the optimal one
overall_reward.append(reward)
optimal_action.append(action == np.argmax(expected_action_value))
# Increment the count for the chosen action
count[action] += 1
# Return the list of rewards and a list indicating if the optimal action was taken at each step
return(overall_reward, optimal_action)
Now, let’s simulate multiple game (each with different epsilon values over 2000 runs) and see the algorithm behaves.
def run_game(runs = 2000, steps = 1000, arms = 10, e = 0.1):
# Initialize arrays to store rewards and optimal action flags for each run and step
rewards = np.zeros((runs, steps))
optimal_actions = np.zeros((runs, steps))
# Generate random expected action values for each arm
expected_action_value = np.random.uniform(0, 1 , arms)
# Iterate over the number of runs
for run in range(0, runs):
# Call the multi_arm_bandit_problem function for each run and store the results
rewards[run][:], optimal_actions[run][:] = multi_arm_bandit_problem(arms = arms, steps = steps, e = e, expected_action_value = expected_action_value)
# After all runs are completed, calculate the average reward at each step
rewards_avg = np.average(rewards, axis = 0)
# Calculate the percentage of times the optimal action was taken at each step
optimal_action_perc = np.average(optimal_actions, axis = 0)
# Return the average rewards and the optimal action percentage
return(rewards_avg, optimal_action_perc)
We ran run_game function for four different epsilon values (e=0, 0.01, 0.1 and 1) and got the following results.
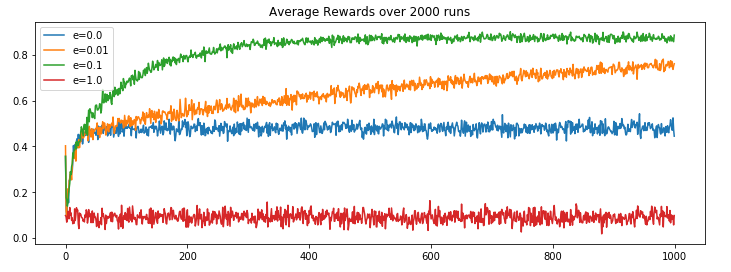
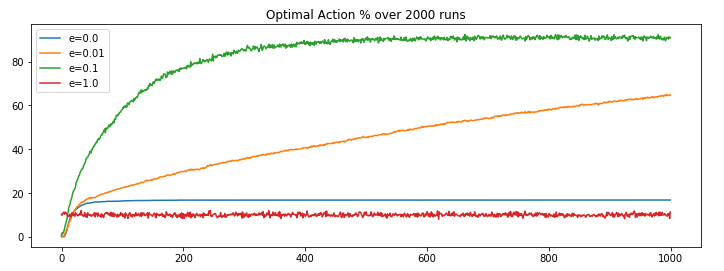
We can observe,
- Complete exploration (
e=1) algorithm has its shortcoming as it never makes use of its leanings, it keep picking actions at random. - Complete exploitation (
e=0) algorithm has its shortcoming as it get locked on the initial best reward and never explore for the sake for better reward discovery. - e(
0.01)-greedy algorithm performs better than the extreme approaches, because of its minute inclination towards exploration and rest of the times going for the best known result. It improves slowly but maybe eventually (too long?) could outperform other approaches. - e(
0.1)-greedy algorithms stands out because it makes use of its learning and from time to time takes exploration initiatives with well distributed probabilities. It explores more and usually find the optimal action earlier than other approaches.
Conclusion
The main take away from this post could be understanding the importance of exploration/exploitation and why a hybrid (0<e<1) implementation outperforms contrast (e=0,1) implementations for the given problem. That said, there are still a number of other approaches which we could have tried like selecting optimistic initial estimate action value, defining an upper confident bound or a gradient based bandit implementation. We also haven’t discussed about the non-stationary problems which increase the complexity of the problem. Well more on this in another post.
Complete code @ Mohit’s Github
Cheers.
Reference
[1] Reinforcement Learning — An Introduction; Richard S. Sutton and Andrew G. Barto