TTS Introduction
Introduction
- Text to Speech (TTS) is the process of generating synthesized speech for a given text input. This is a complicated task as the generating system has to consider context-based pronunciations, tone, rhythm, language, accent, etc. That said, recent research has achieved significant improvement in overall performance.
- Speech synthesis is quite old; in fact, Wolfgang von Kempelen, a Hungarian scientist, constructed a speaking machine with a series of bellows, springs, and bagpipes in the second half of the 18th century.
- Before moving forward, let’s get accustomed to some basic terms related to speech,
- Phoneme: It is the smallest unit of speech. In English language there are a total of 44 phonemes.
- Grapheme: Group of letters that represent speech. Count is 250
- Syllable: Combination of phonemes to create an intelligent pattern of speech. Count is ~15k

Types of TTS
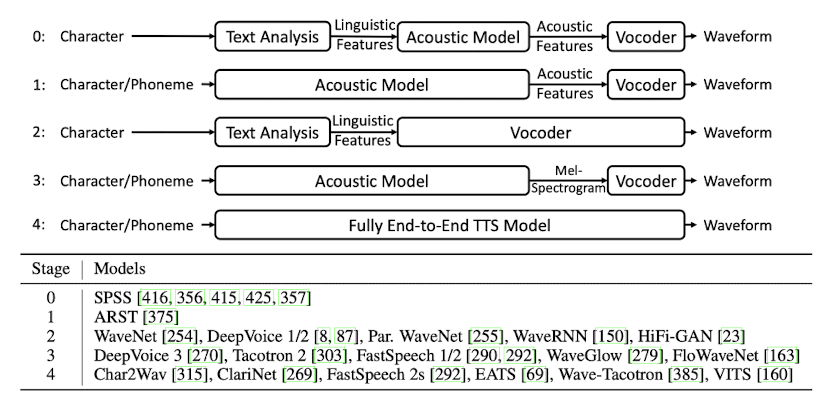
- Let's start with a quick detour of different important types of TTS systems, [1]
- Concatenative Synthesis: Concatenative synthesis is based on combining pieces of speech stored in a database. This database usually contains speech units ranging from full sentences to individual syllables, all recorded by voice actors. There are two major problems with this approach, (a) we require a huge database of recordings (which is nearly impossible if you consider all combinations), and (b) the generated voice is not that smooth.
- Statistical Parametric Speech Synthesis: SPSS usually consists of three components: a text analysis module, a parameter prediction module (acoustic model), and a vocoder analysis/synthesis module (vocoder). The text analysis module first processes the text, and then extracts the linguistic features, such as phonemes, duration and POS tags from different granularities. The acoustic model process the linguistic features to generate acoustic features which is then processed by the vocoder to generate the waveform.
- Neural Speech Synthesis: Recent enhancements in Neural Network (NN) based approaches have led to the use of NN in TTS. Usually, these models takes either of the two approaches, (a) replace one or many of the SPSS components with respective NN models, or (b) use an end-to-end NN based model that replaces all SPSS components with one NN.
Components of TTS
- Next, let’s discuss the components of the SPSS in more detail as they are the common denominator in TTS systems. We will go through them one by one. [1]
- Text analysis: It is used to extract linguistic features from the raw text data. Some common tasks are,
- Text normalization: We can start with converting non-standard words into spoken forms which can make the words easier to pronounce for the TTS models. Ex: year “1989” into “nineteen eighty-nine”
- Word Segmentation: Identifying different words in a text seems trivial in alphabet-based languages like English (use spaces) but it is quite tedious in character-based languages like Chinese.
- POS tagging: Identifying part of speech (like noun, adjective, etc) is important as different words have different pronunciations based on where and how they are used.
- Prosody prediction: Rhythm, stress, intonation corresponds to variations in syllable duration, loudness and pitch. This plays an important part on how human-like the speech is. Prosody prediction used tagging system to label each kind of prosody and ToBI (tagging and break indices) is a popular tagging system for English.
- Grapheme to Phoneme Conversion: Converting characters to pronunciation can greatly help with the speech synthesis process. Ex: “speech” is converted to “s p iy ch”.
- Acoustic Models: They generate acoustic features from linguistics features or directly from phonemes or characters. While there are several models used in SPSS systems, let’s focus on NN based approaches.
- RNN-based models: Tacotron leverages an encoder-decoder framework and takes characters as input and outputs linear-spectrograms, and uses Griffin Lim algorithm to generate waveform. Tacotron 2 generates mel-spectrograms and converts them into waveform using an additional WaveNet model.
- CNN-based models: DeepVoice utilises convolutional neural networks to obtain linguistic features. Then it leverages a WaveNet based vocoder to generate waveform. DeepVoice 2 introduced multi-speaker modeling. DeepVoice 3 leverages a fully-convolutional network structure for speech synthesis, which generates mel-spectrograms from characters and can scale up to real-word multi-speaker datasets.
- Transformers-based models: TransformerTTS leverage transformer based encoder-attention-decoder architecture to generate mel-spectrogram from phonemes. It tackles two flaws of RNN, (a) RNN based encoder and decoder cannot be trained in parallel due to their recurrent nature, and (b) RNN is not good for long generations. While the voice quality is on par with Tacotron, the generations are not that robust (ex: same word repeating multiple times or missing some words). FastSpeech mitigated the issues by adopting fast-forward Transformer network and removing the attention mechanism between text and speech. (It is deployed in AzureTTS services). FastSpeech 2 further improves the overall performance.
- Vocoder: Early neural vocoders such as WaveNet, Char2Wav, WaveRNN directly take linguistic features as input and generate waveform. Later versions take mel-spectrograms as input and generate waveform. Since speech waveform is very long, autoregressive waveform generation takes much inference time. Thus, generative models such as Flow, GAN, VAE, and DDPM (Denoising Diffusion Probabilistic Model, Diffusion for short) are used in waveform generation.
- Text analysis: It is used to extract linguistic features from the raw text data. Some common tasks are,
Evaluating TTS Models
- Benchmarking TTS model is a challenging tasks as we have to consider various aspects of the generated speech like pronunciation, intonation, naturalness, clarity, similarity with speaker, etc. Hence it make sense to have combination of subjective and objective metrics to evaluate a TTS model. Let's discuss some of the metrics,
- Mean Opinion Score (MOS): it is a subjective score where human evaluator are asked to score synthesized speech on a scale of 1 to 5 (higher the better)
- SECS: it stands for "Speaker Encoder Cosine Similarity" and it is used in voice cloning tasks to measure similarity between the generated speech and the reference speech of a target speaker. The idea is that if the generated speech is really good wrt voice cloning perspective, then the speaker encoders will give relatively similar embeddings to the output and reference speech and the SECS should be high.
- Word Error Rate (WER): WER can also be used in TTS domain to make sure that the generated speech is coherent with the reference speech.
Hint
For any one project, make sure to use the same speaker encoder for SECS and transcription system for WER metric computation.
Code
- There are lot of open source python package for TTS like Coqui TTS, Mozilla TTS, OpenTTS, ESPNet, PaddleSpeech, etc. Let's go through some of the most famous and easy to use ones,
Coqui TTS
- For this tutorial, let's use Coqui TTS as it is one of the simplest package in terms of usability. In fact you just need to install the package with
pip install TTSand then run the server withtts-server, and thats it! It will run a http dashboard on the localhost woth default model and vocoder like shown below,

- I tried it for
"my name is Mohit"text and the result is shared below. Btw you can switch to different models or speakers to get different sounding speech.
- You can check out other models and vocoder available in the package with
tts-server --list_models. Note, not all models and vocoder pairs are comparable. On top of this, Coqui TTS also provides the option to train and finetune the models further!
OpenTTS
- Another good package is OpenTTS that unifies access to multiple open source text to speech systems and voices for many languages.
- One distinctive feature is the partial support to SSML i.e. Speech Synthesis Markup Language. It is a XML-based markup language for assisting the generation of synthetic speech in Web and other applications. One example as shared in their readme is shown below,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
- SSML support can lead to generation of complex and realistic sound as you can add sentence breaks, pauses, handle spelling out of numbers or date, change model or even languages for a single generation!
- The package is quite simple to run. First you need to install
docker, and then download and run a docker image withdocker run -it -p 5500:5500 synesthesiam/opentts:<LANGUAGE>, where<LANGUAGE>could be any of the 20 supported langauge. To begin with you can tryen. - The downloading will take some time (more than 5GB is downloaded!) but once done, you can access the dashboard on
http://localhost:5500or hit the HTTP APIs onhttp://localhost:5500/openapi/. The endpoint details can be found here and the complete list of voices generated by the available models is shared here.
- I tried it for text
"Hello, how are you? My number is 7350."by selecting thecoqui-tts: vctkmodel andED (0)speaker. The output is quite good and shared below,
Additional Materials
[1] Paper - A Survey on Neural Speech Synthesis
[2] Speech synthesis: A review of the best text to speech architectures with Deep Learning