Question Answering
Introduction
-
As the name suggests, Question Answering (QA) is a NLP task of finding answer given the question and context (optional). QA could be of two types based on the input,
-
Open-domain QA: where context is not provided. The expectation is that the model has internalised knowledge within its parameters and should be able to answer the question with additional context.
graph LR A("Who is the author of Lazy Data Scientist?") -- Question --> B(QA model) B -- Answer --> C("Mohit") style B stroke:#f66,stroke-width:2px,stroke-dasharray: 5 5
-
Closed-domain QA: where context is provided. The expectation is that the model has learned to find answers from context.
graph LR A("Who is the author of Lazy Data Scientist?") -- Question --> B(QA model) D("Hi, my name is Mohit. I am the author of Lazy Data Scientist!") -- Context --> B(QA model) B -- Answer --> C("Mohit") style B stroke:#f66,stroke-width:2px,stroke-dasharray: 5 5
-
-
Answers could be also be of two types,
-
Short form Answers: where the answer is brief and to the point.
- In the above examples, the answer (
Mohit) is in short form. Majority of the closed domain QA models generate short form answers as they follow extractive approach of finding answer. - For this, encoder based architectures (like BERT) can be used. The input can be provided as
[CLS] question [SEP] context [SEP] - As output, we compute probabilities of two special logits -- answer start and answer end. This gives the exact position of the answer. In reality, we apply softmax on the output logits values to get probabilistic estimation for each token in the input.
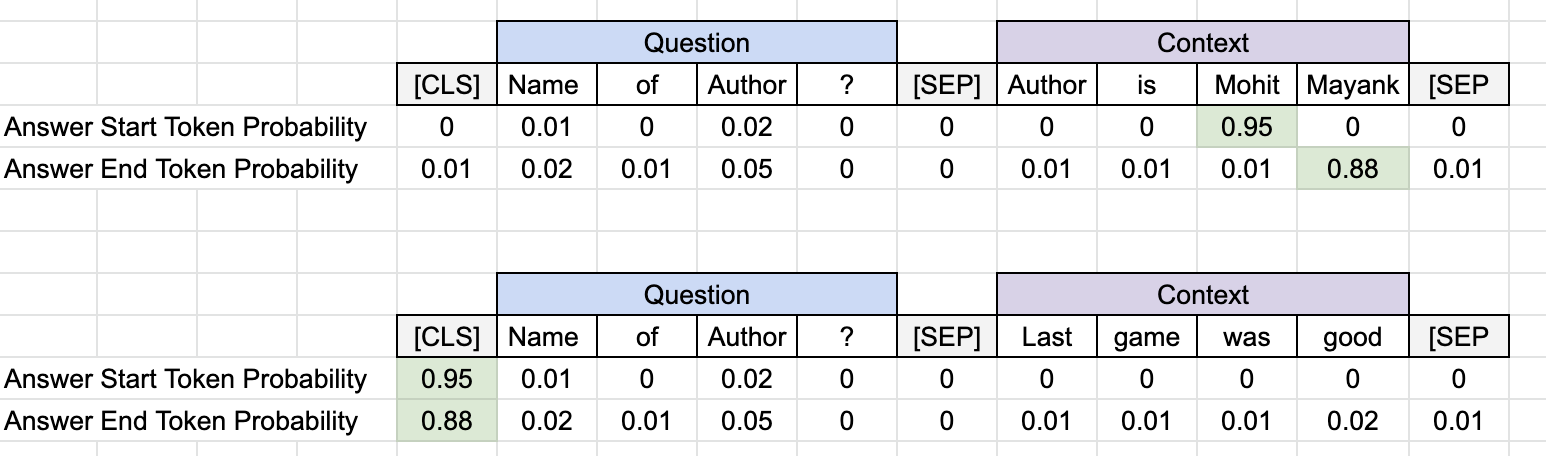
Behavior of Short form closed QA system. [Top] In case the answer is present in the context, answer start and end token's probabilties can be utilised to get the answer. [Bottom] In case answer is missing, [CLS] is predicted. - We pick the pair (answer start and end logit) that has the highest probability (product of their individual probability) and it's a valid answer (answer with positive or zero length and answer with tokens only from context). If we go greedy i.e. pick the
top_n = 1for both logits, we will get the pair with the highest probability but it is not guaranteed to be a valid answer. - To mitigate this, we pick
top_n(~10-20) highest probability tokens for both start and end answer values. This gives us \(n^2\) possibilities of answers that can be explored to find the valid answer.
Note
To solve similar tasks, BERT utilises different task specific heads on top of the BERT encoder. In the case of QA, a head could be simple feed forward layer with two classes - answer start and answer end. The same head is applied to each token in the BERT output, and probability of the both classes are computed.
- In the above examples, the answer (
-
Long form Answers: where the answer is descriptive, standalone and may also contain additional details.
- For the above example, long form answer could be
Mohit is the author of Lazy Data Scientist. - We can use additional models like LLM (GPTs, T5, etc) on top of QA system to convert short form answers to long form. Existing model will require finetuning with the Question and Short form answer as input and Long form answer as output.
- We can even try to n-shot the process using LLMs as shown in the following prompt:
Question: What is the author's name? Context: Author is Mohit Mayank. Short answer: Mohit Mayank. Long answer: Author's name is Mohit Mayank. ## provide 2-3 examples as above Question: What is the captial of India? Context: India's new captial New Delhi was setup with .... Short answer: New Delhi Long answer: # let the model predict long form answer!!
Note
Perplexity AI is a good example that uses GPT 3.5 to generate long form answers and even provide evidences for the answer. First, it performs web search using Microsoft Bing to identify relevant websites and the contents are summarized. The summaries are then passed to GPT along with the original question to answer the question with the reference details for the evidence.
- For the above example, long form answer could be
-
Datasets
SQuAD
- Stanford Question Answering Dataset (SQuAD) [2] is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable. There are two verisons of the dataset,
- SQuAD 1.1 contains 100,000+ question-answer pairs on 500+ articles.
- SQuAD2.0 combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
Metrics
Exact Match
- As the name suggests, for each question we compare the golden answer with the predicted answer. If the two answers are exactly similar (
y_pred == y_true) thenexact_match = 1elseexact_match = 0.
F1 score
- There is a possibility that the predicted answer includes the important parts of the golden answer, but due to the nature of exact match, the score is still 0. Let's understand it with an example, here ideally the score should be high (if not 1), but exact match will give 0.
- Question: When can we meet?
- Golden answer: We can meet around 5 PM.
- Predicted answer: 5 PM.
- For such cases we can perform partial match. Below is the example,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# vars to begin with predicted_answer = 'Hi, My name is Mohit' golden_answer = 'My name is Mohit' # tokenize predicted_words = set(predicted_answer.lower().split()) golden_words = set(golden_answer.lower().split()) # find common words common_words = predicted_words & golden_words # compute metrics recall = common_words / predicted_words precision = common_words / golden_words F1 = 2 * precision * recall / (precision + recall)
Note
In case one question has multiple independent answers, we can compare each golden answer for the example against the prediction and pick the one with highest score. The overall accuracy is then the average of the individual example level score. This logic can be applied to both the metrics discussed above.
Code
Using Transformers (HF hub)
- Huggingface hosts multiple models for the QA task. Most of these models are fined tuned on SQuAD dataset. Let's pick one and see how to use it.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
References
[1] Evaluating QA: Metrics, Predictions, and the Null Response
[2] SQuAD Explorer
[3] How to Build an Open-Domain Question Answering System?
[4] Question Answering - Huggingface
Cheers 