T5
Introduction
- T5 stands for "Text-to-Text Transfer Transformer". It was released by Google on 2020. As the name suggests, it's a tranformer based encoder-decoder model used for text generation. For more details about other text generation models, refer the Text Generation chapter.
- In contrast to other famous Transformer based models like BERT or GPT, which is made up of either the encoder or decoder part of the Transformer, T5 paper showcase that using the complete encoder-decoder architecture is better than only using decoder. Apart from this, the paper also curated and released Colossal Clean Crawled Corpus (C4) - a huge crawled and cleaned dataset for pre-training language model using self-supervised learning. (raffel2020exploring)
![]()
- Due to this nature of T5, for training or finetuning, the model requires a pair of input and output sequences/text. Some example tasks that can be performed using T5 is shown below,

-
Based on the original T5, there has been several variations explored such as, (refer T5 @ HuggingFace )
- T5v1.1: T5v1.1 is an improved version of T5 with some architectural tweaks, and is pre-trained on C4 only without mixing in the supervised tasks.
- mT5: mT5 is a multilingual T5 model. It is pre-trained on the mC4 corpus, which includes 101 languages.
- byT5: byT5 is a T5 model pre-trained on byte sequences rather than SentencePiece subword token sequences.
- Long-T5: For use case where we need to process longer input (Refer)
Note
As mentioned above, for multi-lingual purpose refer mT5 which was trained on >100 languages. That said, original T5 was also trained on translation task from English to German, French and Romanian. So the output can sometimes contains tokens from these languages!
Paper details
Transformer Architecture
- To compare different architectures suitable for languague models, T5 authors considered basically three varieties,
- Encoder-Decoder: A standard encoder-decoder architecture uses fully visible masking in the encoder and the encoder-decoder attention, with causal masking (attention mask) in the decoder. Masking is done to make sure the output at a position doesn't attend to future output for prediction.
- Language model: A language model consists of a single Transformer layer stack and is fed the concatenation of the input and target, using a causal mask throughout. As usual with LMs, the output only attends to the past input or output.
- Prefix LM: Adding a prefix to a language model corresponds to allowing fully-visible masking over a portion of the input. It is very similar to LM, just that any output will attend to a certain portion of the input that contains prefix could could contain task specific information like
translate English to German:.
![]()
- T5 found the transformer based architecture to perform better than others.
Pre-training Strategy
- T5 is trained with multi-task learning methodology, where the idea is to club multiple tasks while pre-training the model. These multiple tasks are further clubbed into two groups based on how they are trained,
- Unsupervised training:
- this includes training on the C4 dataset using the classic language model training tasks with maximum likelihood objective.
- For unsupervised tasks like MLM, T5 has 100 special tokens
<extra_id_0>to<extra_id_99>which can be used to format the input and output text. For the sentence "My name is Mohit Mayank" where I want to mask "name is", the input isMy <extra_id_0> Mohit Mayankand required output will be<extra_id_0> name is <extra_id_1>.
- Supervised training:
- this includes adding several NLP based tasks like question-answering, summarization, classification, etc. The model is trained with the curated training data in a supervised fashion, but all these tasks are transformed to work with text-in text-out format as suitable for encoder-decoder models.
- The data for supervised training is created separately for input and output text. For input it looks like
{task_prefix}: {input_sequences}</s>. Similarly for the output text it looks like<pad> {output_sequence}</s>. One example could be:translate English to German: The house is wonderful.</s>for input and<pad> Das Haus ist wunderbar.</s>for output. This is then passed to the model to compute loss on the output part and then backpropagated to decrease the loss.
- Unsupervised training:
Note
T5 authors also released checkpoint models which are only unsupervised trained on the C4 dataset. More details and model is available here.
- T5 also compared different unsupervised objectives i.e. different training stratigies for unsupervised training which could lead to better performance. A visual guide to the search space is shown below.
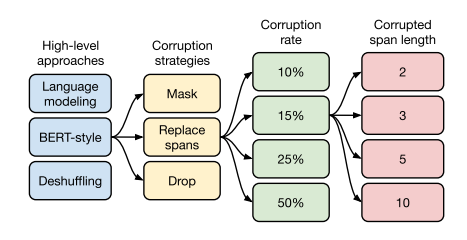
- To begin with, there were three High-level approaches, (1) Language modeling: where you take predict the next word based on historical words, (2) BERT-style: where you mask certain words and model predict those masked words, or (3) Deshuffling: where you shuffle the sentence and model predicts the unshuffled correct sentence as output. After experimenting with these BERT-style approach gave the best result and hence was selecte for next level of analysis.
- Next, different corruption startegies were tried. Originally BERT proposed MASD based approach but for language model setting, T5 authors observed Replace span works better. In replace span you mask consecutive tokens and language model predicts the masked spans.

- Finally, different rate of corruption rate and corruption span length were experimentally selected.
Performance score
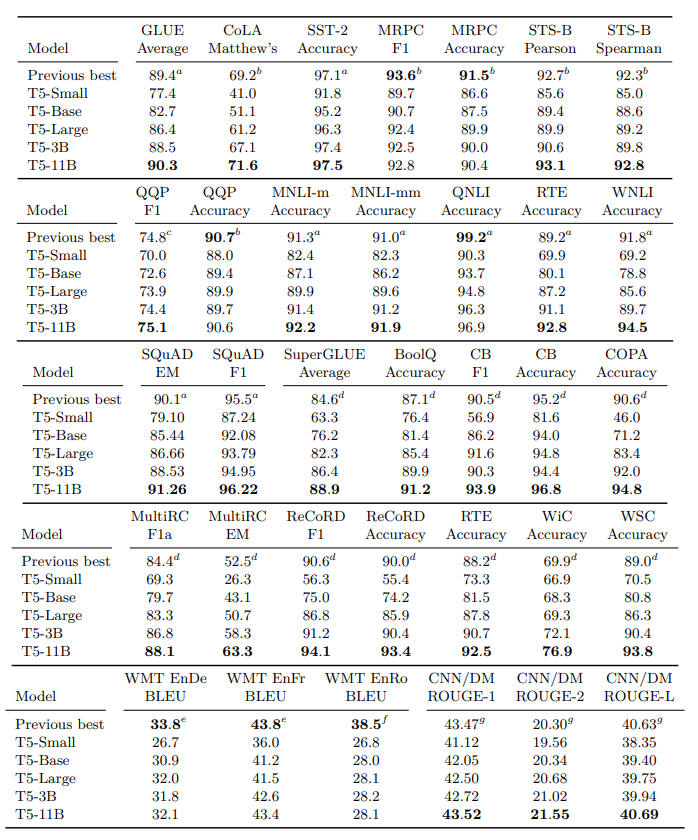
- T5 paper reports following performance score on different datasets,
Code
T5 Inference
- Running T5 is super easy using HuggingFace. Let's do it,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
T5 finetuning
- Before we dive into finetuning, here are some tips if you are going to use PyTorch or Keras.
- We can use high learning rate for AdamW optimizer in range of 1e-4 and 3e-4. Btw T5 was originally pre-trained with AdaFactor optimizer.
- We can add task specific prefix like
translate English to German:orsummarize:in the input sequence if your task is similar to the ones T5 was originally pre-trained with. - We should replace the PAD token ids 0 with -100 so that it is ignored from loss computation. Btw PAD token is used as start sequence token for the labels (text that is to be generated).
- To keep things simpler, we can use SimpleT5, an excellent package that abstract a lot of technicalities. For dataset, we can go with Tweet sentiment data, that can be downloaded from here
- Some differences from training other text generation models (due to the SimpleT5 package),
- We don't need the
Datasetclass, as SimpleT5 works directly on pandas dataframe. Hence we load the data, do some initial pre-processing, split the data and return the pandas dataframe. (no need to tokenize, create Dataset class, isn't this great!?) - One more point to note is that we do not need to create prompt formats for this package. This way we can separate out the input tweet and sentiment label into different columns, here
source_textandtarget_text, respectively (Line 29 and 30).
- We don't need the
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 | |
References
[1] Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer - Link