Reinforcement Learning from Human Feedback (RLHF)
Introduction
- In Reinforcement learning, an agent learns to perform a task by interacting with an environment and receiving rewards or penalties for its actions. While this approach has shown great success in a wide range of applications, it can be difficult to design reward functions that accurately capture the user's preferences.
- Take autonomous driving car as an example, instead of creating a complicated reward function (with metrics like follow the lane, on wet road drive slow, stop at stop sign, don't hit anyone, etc and their weightage) we might want to let AI learn it. One point to note, we also do not want AI to learn to imitate human drivers, but rather learn what humans value in driving behavior and then optimize against those preferences.
- Because of this, we not only want trajectories (episodes or examples), but also some form of feedbacks on different trajectories stating which one is better than the other. Once we have this, we can train a model to first learn the reward function (Inverse Reinforcement Learning) and later use the same reward to train an expert model (Apprenticeship learning)
- In this article, we will start with understanding the fundamentals of different types of human feedback, how to use them with RL and their pros and cons. Finally, we will discuss application of RLHF in NLP with tasks like Summarization. Let's start

Types of human feedback
There are different types of human feedback that can be used in reinforcement learning. These include:
- Explicit feedback: This type of feedback is direct and clear. It involves a human providing a specific reward or penalty to reinforce or discourage certain behaviors. For example, a teacher might provide explicit feedback to a student by giving them a grade for their performance.
- Implicit feedback: This type of feedback is more subtle and indirect. It involves a human providing information about what they like or dislike without explicitly stating it. For example, a customer might provide implicit feedback to a restaurant by choosing to visit it again or not.
- Comparison-based feedback: This type of feedback involves a human comparing the performance of an agent to that of another agent or a benchmark. For example, a manager might provide comparison-based feedback to an employee by comparing their performance to that of other employees in the same position.
Incorporating human feedback
There are several methods for incorporating human feedback in reinforcement learning, including:
- Reward shaping: This method involves modifying the reward function to incorporate human feedback. The goal is to manually guide the learning process towards behaviors that are more aligned with the user's preferences. For example, if a user wants a robot to clean a room quickly and efficiently, the reward function can be modified to encourage the robot to complete the task as quickly as possible.
- Imitation learning: This method involves learning from demonstration. The agent observes a human expert performing a task and learns to mimic their behavior. This method is particularly useful when the task is complex and difficult to learn from scratch. For example, a robot can learn to fold laundry by watching a human expert do it.
- Inverse reinforcement learning: This method involves inferring the reward function from human demonstrations. The agent observes a human expert performing a task and tries to learn the underlying reward function that motivated the expert's behavior. This method is particularly useful when the user's preferences are not easily expressed in terms of a reward function. For example, a robot can infer the reward function that motivated a human expert to perform a task and then optimize its behavior accordingly.
These methods can be used alone or in combination to incorporate human feedback in reinforcement learning. The choice of method depends on the nature of the task, the type of human feedback available, and the computational resources available for learning.
Benefits and challenges of using human feedback
Using human feedback in reinforcement learning has several benefits, but also presents some challenges.
Benefits
- Improved efficiency: Incorporating human feedback can accelerate the learning process and reduce the number of trials required to learn a task. By providing feedback that guides the agent towards desirable behaviors, human feedback can help the agent focus on the most promising strategies.
- Better performance: Human feedback can improve the quality of the learned policy and increase the success rate of the task. By incorporating the user's preferences, the agent can learn to optimize its behavior for the specific context of the task.
- Increased interpretability: Human feedback can make the learned policy more transparent and interpretable. By understanding the user's preferences, the agent can provide explanations for its actions and provide insights into how it works.
Challenges
- Quality of human feedback: The quality of human feedback can vary depending on the user's expertise, knowledge, and ability to articulate their preferences. Some users may have conflicting preferences or provide ambiguous feedback, which can make it difficult for the agent to learn effectively.
- Bias and subjectivity: Human feedback can be biased and subjective, depending on the user's cultural background, personal beliefs, and emotional state. These factors can introduce bias into the learning process and make it difficult to generalize the learned policy to different contexts.
- Limited scalability: Incorporating human feedback can be resource-intensive and may not be feasible for large-scale applications. Collecting and processing feedback from multiple users can be time-consuming, and the resulting models may not be generalizable to new users.
RLHF in NLP
- Reinforcement learning from human feedback (RLHF) has shown great potential in improving natural language processing (NLP) tasks. In NLP, the use of human feedback can help to capture the nuances of language and better align the agent's behavior with the user's expectations.
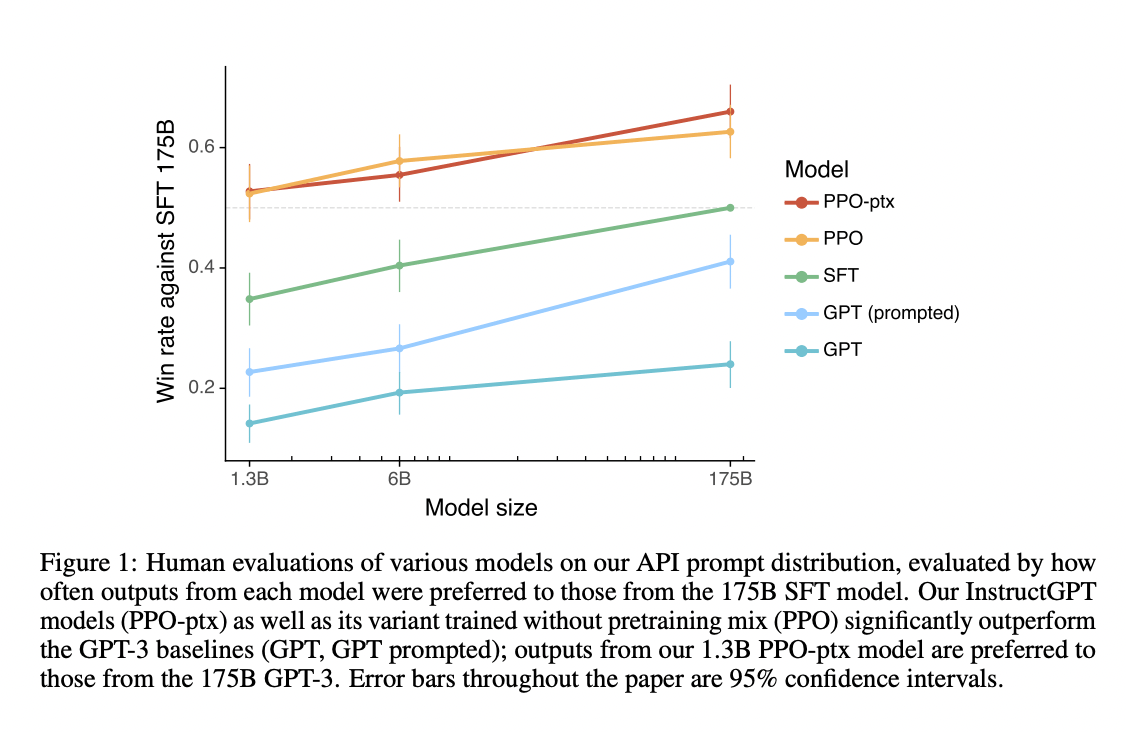
Summarization
- One of the first examples of utilizing RLHF in NLP was proposed in [1] to improve summarization using human feedback. Summarization aims to generate summaries that capture the most important information from a longer text. In RLHF, human feedback can be used to evaluate the quality of summaries and guide the agent towards more informative and concise summaries. This is quite difficult to capture using the metrics like ROUGE as they miss the human preferences.
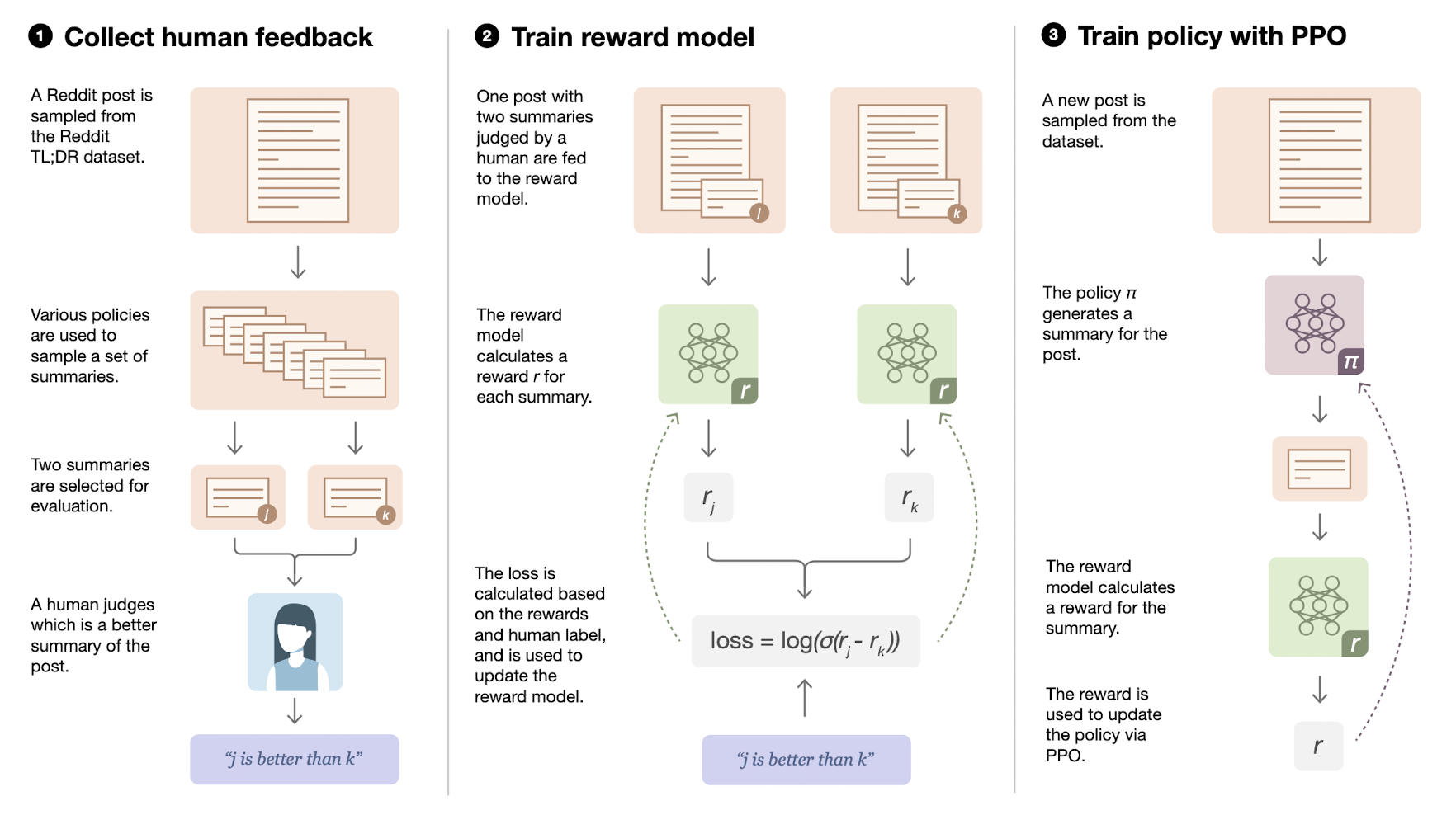
- The overall process was as follows,
- First, an autoregressive model is trained via supervised learning on the dataset (TL;DR dataset with >120k post from reddits and their summaries were taken). The resulting model is termed as initial policy.
- Then the following steps are performed in iteration,
- For each reddit post, samples from initial policy, current policy (for step 0 its same as initial policy), other baselines, and original summaries are taken and send over to human labelers.
- Based on human labelers's feedback, we now have candidate summary for each post. We use this data to train a reward function (linear layer on initial policy) using supervised learning.
- The output of reward function is treated as the reward to optimize using the reinforcement learning (authors use PPO algorithm).
- To shed more light on the how policies are trained using rewards, the finetuned model is treated as initial policy. In RL terminology, state is the prompt plus the generations so far, action is token to generate, each step is one token generation and one episode terminates when policy returns
<EOS>token. Also, the reward function gives score for the complete summary and not individual generations. - Finally, a conditioning term in added to the final reward that penalizes the KL divergence between the learned RL policy and the original supervised model. Quoting the paper, "This KL term serves two purposes. First, it acts as an entropy bonus, encouraging the policy to explore and deterring it from collapsing to a single mode. Second, it ensures the policy doesn’t learn to produce outputs that are too different from those that the reward model has seen during training."
ChatGPT like Dialog Systems
- Probably the most famous use case of RLHF in NLP was to finetune the raw ChatGPT model to make it a more dialog friendly system. In a dialog system, the aim is to generate responses to user inputs that are coherent, informative, and relevant to the user's goals. In RLHF, human feedback can be used to evaluate the quality of generated responses and guide the agent towards more effective communication strategies. For example, a user can provide explicit feedback on the relevance of a response, or implicit feedback by continuing or ending the conversation.
Conclusion
- While RLHF has shown promise in improving NLP tasks, there are still challenges related to the quality of human feedback and the scalability of the approach. Collecting and processing human feedback can be time-consuming and may not be feasible for large-scale applications. Furthermore, human feedback can be subjective and may not capture the full range of user preferences. However, as RLHF continues to be refined, it has the potential to greatly enhance the quality and effectiveness of NLP systems.
References
[1] Learning to summarize from human feedback
[2] Training language models to follow instructions with human feedback