LLaMA - 1, 2
Introduction
- In Feb 2023, Meta introduced a collection of foundation language models ranging from 7B to 65B parameters under the name of LLaMA.
- What makes LLaMA different from other LLMs is,
- It was trained on 1.4 trillion tokens created using publicly available datasets without resorting to proprietary and inaccessible datasets as done by the likes of Chinchilla, PaLM, or GPT-3.
- With added improvements, the resulting models are highly competitive against more powerful models. For instance, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA- 65B is competitive with the best models, Chinchilla-70B and PaLM-540B.
Tip
“Official” weights were only released to the research community and even then you need to fill out a form to request access.
That said, there has been “pirating” of the weights that allow anyone to play around with the model. It was quite interesting, more details in this LinkedIn Post 
- LLaMA-2 [3] was announed on July 2023 which was trained on 40% more data (~2 Trillion tokens) than LLaMA-1 and has double the context length (4096 tokens). Learning from the social media reactions with LLaMA-1, v2 was released for both research and commerical purpose!
Architecture Modifications
To achieve the enhancements, several modifications were made to the original Transformer architecture. They are, [1]
- Pre-normalization [from GPT3] To improve the training stability, RMSNorm was used to normalize the input of each transformer sub-layer instead of the output.
- SwiGLU activation function [from PaLM]. ReLU non-linearity was replaced by the SwiGLU activation function.
- Rotary Embeddings [from GPTNeo]. Absolute positional embeddings were replaced with rotary positional embeddings (RoPE) at each layer of the network.
Training Optimizations
On top of architecture modifications, several optimizations were made to improve the training speed of the models. They are, [1]
- First, an efficient implementation of causal multi-head attention was used to reduce memory usage and runtime. (refer
xformerslibrary) - To further improve training efficiency, the number of activations that are recomputed was reduced during the backward pass with checkpointing.
- Additional GPU optimizations were done like overlapping the computation of activations and the communication between GPUs over the network.
Dataset
- The dataset used to train LLaMA-1 was created using only open-source data and is a mixture of several sources, as shown below. This led to the creation of 1.4 Trillion tokens of the total dataset. [1]
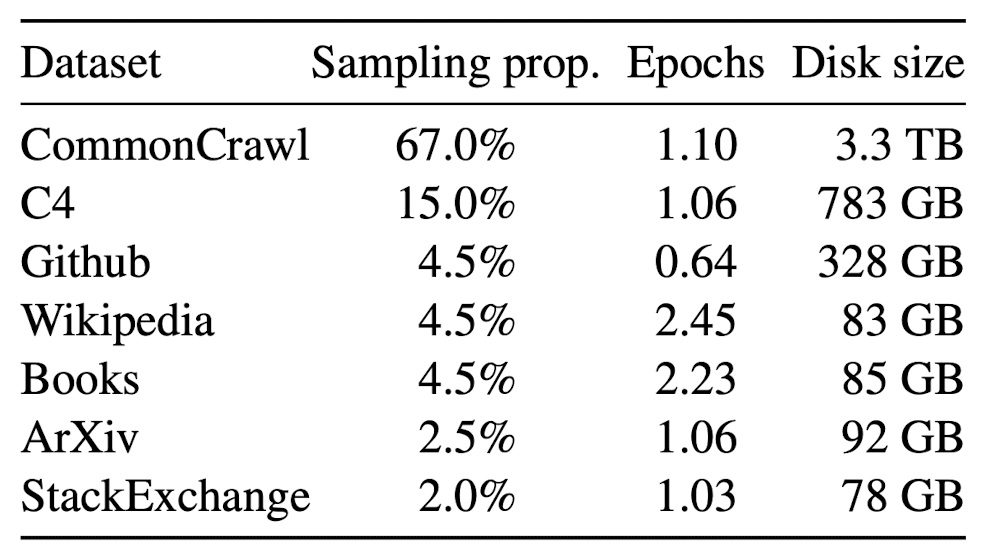
- In LLaMA-2 the dataset size was increased to 2 Trillion tokens by including a new mix of data from publicly available sources, which does not include data from Meta’s products or services. Meta removed data from certain sites known to contain a high volume of personal information about private individuals.
Released Models
- For LLaMA-1, below is the list of models trained as part of the project with additional details like dimensions, attention layers and head as well as the training metrics of the learning rate, batch size and the number of tokens used for training. [1]
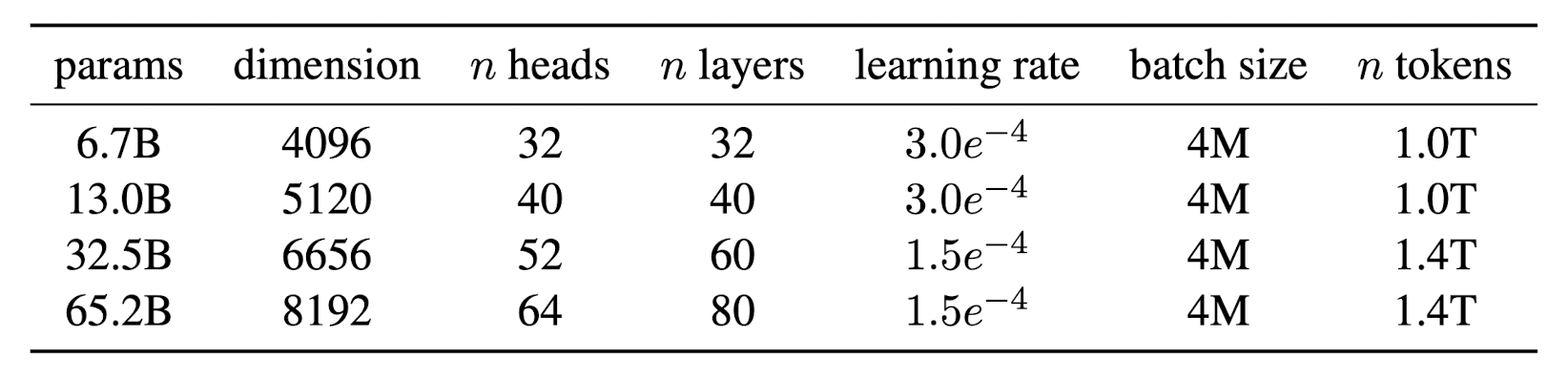
- Under LLaMA-2 only three models 7B, 13B and 70B were released.
Inspired Models
LLaMA was one of the first opensource work on making powerful LLM accessible to the public. This has inspired release of several similar models, below are some of them.
Alpaca
- LLaMA authors observed that a very small amount of instruction-based finetuning improves the performance of the model on Massive Multitask Language Understanding Tasks (MMLU). It also further improves the ability of the model to follow instructions. That said, they didn’t explore this thread further. Below you can see 5-shot MMLU performance of LLaMA-Instruct model (LLaMA-I) -- it is better than LLaMA model of the same size. [1]
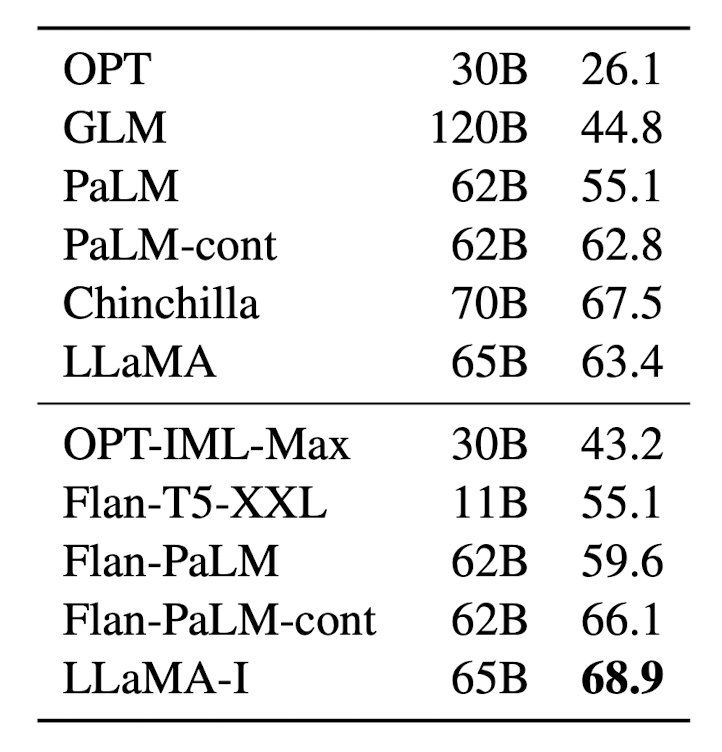
- Enter Stanford Alpaca [2], an instruction-based finetuned LLaMA that further improves the performance of LLaMA models so much so that even 7B Alpaca model is comparable with OpenAI’s text-davinci-003.
Warning
Alpaca team suggested that the model is better than LLaMA. There were no comparitive numbers or tables shared.
- The process starts with first generating 52K instruction-following samples using OpenAI's text-davinci-003. Then LLaMA model was finetuned on these data using supervised learning, basically taking inspiration from self-instruct paper. This process reduces the cost of preparing a GPT level model to under ~ $600 ( $500 to generate the data + $100 to finetune). The process is summarised below,
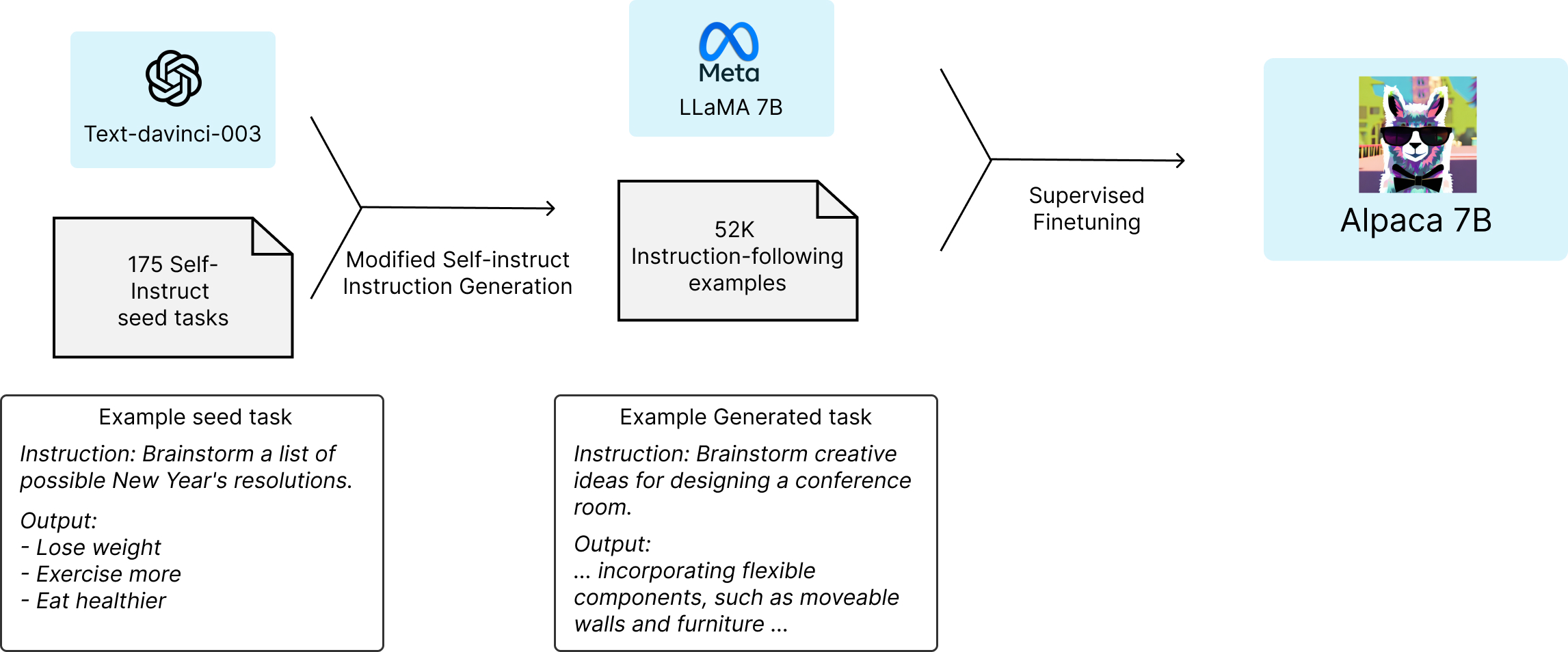
Note
The code to generate the 52k dataset along with finetuning recipe was open-sourced [2]
OpenLLaMA
- OpenLLaMA [4] is a permissively licensed open-source reproduction of Meta AI's LLaMA, providing a series of 3B, 7B, and 13B models trained on 1T tokens. OpenLLaMA was trained on the RedPajama dataset and other diverse datasets using cloud TPU-v4s with the EasyLM framework, employing data parallelism and fully sharded data parallelism to enhance efficiency. The models are available in PyTorch and JAX formats. OpenLLaMA's evaluation showcases its comparable and sometimes superior performance across various tasks to the original LLaMA and GPT-J models, reflecting its robustness and reliability.
- The project was quite active in 2023 with release of v2 and v3 models which was trained on mixture of Falcon refined-web dataset, the starcoder dataset, the wikipedia, arxiv, books and stackexchange from RedPajama. Below is a sample code from their Github [4],
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
TinyLLaMA
- TinyLlama is an ambitious open-source project aimed at pretraining a 1.1B parameter Llama model on 3 trillion tokens, striving for both efficiency and compactness. With the goal of completing this massive training within 90 days using 16 A100-40G GPUs, the project began its journey on September 1, 2023. TinyLlama maintains the same architecture and tokenizer as the original Llama model, ensuring compatibility and ease of integration with various existing open-source projects. What sets TinyLlama apart is its compact size, enabling it to be utilized in numerous applications that demand reduced computation and memory footprint, making it particularly suitable for deployment in resource-constrained environments.

- The training utilizes a vast dataset, combining Slimpajama and Starcoderdata to comprise approximately 950 billion tokens, with the total tokens during training reaching 3 trillion. The project is noted for its adaptability and speed, offering multiple optimizations to enhance performance, such as multi-GPU and multi-node distributed training, flash attention 2, and fused operations for LayerNorm, SwiGLU, cross entropy loss, and rotary positional embedding. The models can be found in their HuggingFace Org page.
Note
As mentioned above, the total dataset size was 950B but as the model was trained for approx 3 epochs the total trainable tokens are 3 Billions.
Another point to note is that this model was motivated by the model training saturation details mentioned in LLaMA-2 paper. It shows every model from 70B to 7B are still not saturated even after training for 2B tokens. This approach was an extrapolation on the research by picking a much smaller model (~1B) and going much further (3B tokens).
LiteLLaMA
LiteLlama-460M-1T[6] is a model with 460 million parameters, trained on approximately 1 trillion (0.98T) tokens. It leverages the RedPajama dataset for training and utilizes GPT2Tokenizer for text tokenization, preserving high compatibility and performance while reducing the model's size.
- In terms of evaluation, LiteLlama-460M-1T has been assessed on multiple datasets, but MMLU task showcase its comparative performance when compared to TinyLLaMA. The project, developed by Xiaotian Han from Texas A&M University, emphasizes the open-source ethos by making the model and training details accessible and by releasing it under the MIT License (available here).
Note
Just because LiteLLaMA works good for one task does it not mean it can replace TinyLLaMA or LLaMA-2 models completely. Make sure to perform extensive test for your usecase before selecting any model.
Code
Inference
There are many ways to access LLaMA. Below are some of the most popular ones,
HuggingFace
- HuggingFace has created the port to use the LLaMA-1 model. You can also access the crowd-uploaded model at the hub here. The code to load and use the model like any other LLM is shown below,
1 2 3 4 5 6 7 8 9 10 | |
- With LLaMA-2 we have the official model weights uploaded on HuggingFace from Meta. The code remains the same, we just have to modify the model name. One exmaple of the model is meta-llama/Llama-2-13b-hf, and you can find more models on the Meta LLaMA Org page.
Dalai
- Dalai is the simplest way to run the LLaMA-1 or Alpaca models on your machine. It also provides an intuitive UI to use the model. All you need to do is,
1 2 3 4 5 6 | |
- And it looks good! 👇

Note
Internally it uses C/C++ port of LLaMA and Alpaca. You can access them separately for faster execution. The respective packages have also applied quantization to provide much faster execution with some compromise on accuracy.
Finetuning
While there are multiple ways to finetune LLaMA model, we will focus on QLoRA based finetuning as this is the most efficient and fast way to create adapters on top of LLaMA for any downstream tasks. Below is the code to finetune Llama-2-7b-chat-hf model for a classification task and it can be easily modified (by changing the model name) to work for other similar models,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 | |
Hint
If you are getting this or similar error -- No libcudart.so found! Install CUDA or the cudatoolkit package (anaconda)! due to bitsandbytes pacakge, you can fix it by running following code on your system after installing the packages. But make sure to check of the following path and files are available or not.
1 2 3 4 | |
Hint
If you want to perform normal inference after loading the model at `line 44`` above, you can use the following code,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
References
[1] LLaMA-1 - Official Model Card | HuggingFace | Release Blog | Paper
[2] Alpaca - Release Notes | HuggingFace Model | Github
[3] LLaMA-2 - Release Blog | Paper
[4] OpenLLaMA - Github
[5] TinyLLaMA - Github | Models
[6] LiteLLaMA - Models