Word2Vec
- Word2Vec (w2v) [1] is a word embedding technique that represents a word as a vector. Each vector can be thought of as a point in \(R^{D}\) space, where \(D\) is the dimension of each vector.
- One thing to note is that these vectors are not randomly spread out in the vector space. They follow certain properties such that, words that are similar like "cat" and "tiger" are relatively closer to each other than a completely unrelated word like "tank".
- In the vector space, this means their cosine similarity score is higher. Along with this, we can even observe famous analogies like \(king - man + woman = queen\) which can be replicated by vector addition of these word's representation vector.
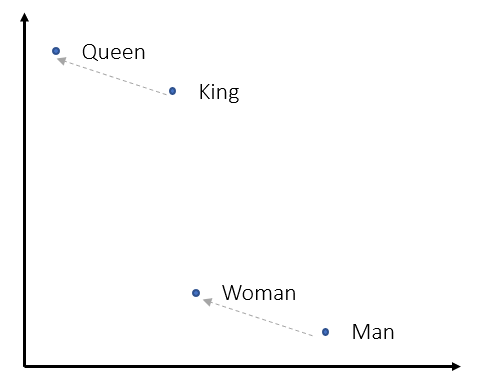
- While such representation is not unique to w2v, its major contribution was to provide a simple and faster neural network based word embedder.
- To do so, w2v transformed the training as a classification problem. The neural network tries to answer which word is most probable to be found in the context of a given word. Given a sequence of words that "naturally" appears in some sentence, the input could be any middle word and output could be any of the surrounding words (within some window). The training is done by creating a 1-layer deep neural network where the input word is fed as one-hot encoding and output is softmax applied with intention of getting large value for context word.
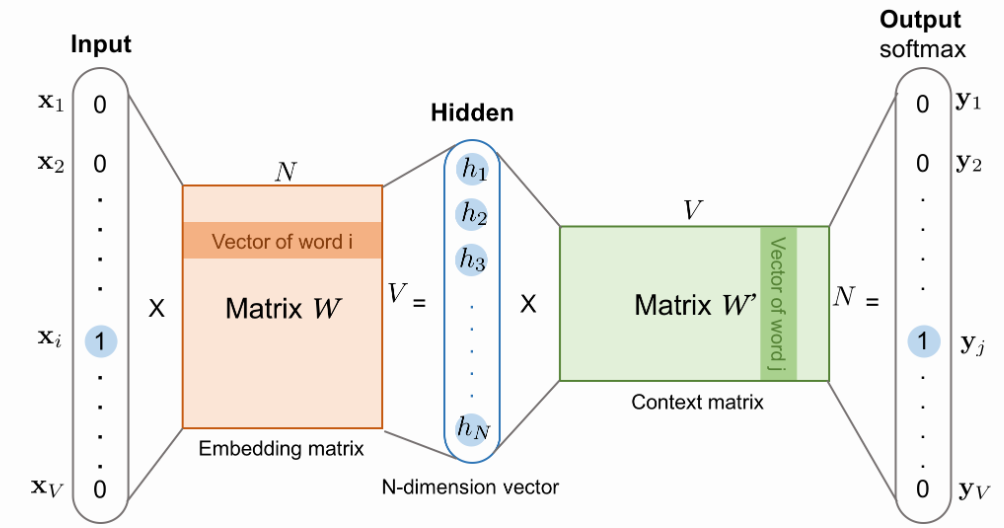
- The training data is prepared by sliding a window (of some window size) across the corpus of large text (which could be articles or novels or even complete Wikipedia), and for each such window the middle word is the input word and the remaining words in the context are output words.
- For each input word in vector space, we want the context words to be close but the remaining words far. And if two input words will have similar context words, their vector will also be close.
- Word2Vec also performs negative sampling, wherein random selection of some negative examples are also added in the training dataset. For these examples, the output probabilities should be \(0\). [4]
- After training we can observe something interesting — the weights between the Input-Hidden layer of NN now represent the notions we wanted in our word embeddings, such that words with the same context have similar values across vector dimension. And these weights are used as word embeddings.
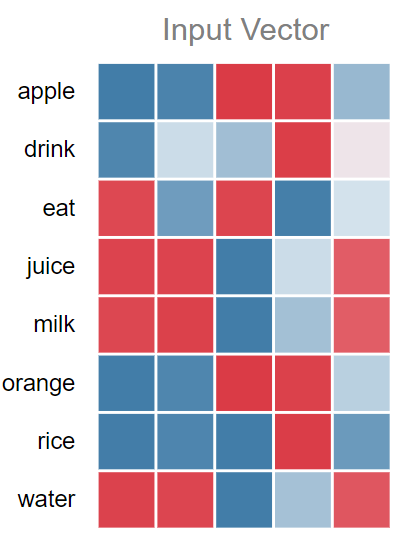
- The result shown above is from training 5D word embeddings from a cool interactive w2v demo tool called "Wevi" [3].
- As visible, words like (juice, milk, water) and (orange, apple) have similar kinds of vectors (some dimensions are equally lit — red or blue).
Hint
One obvious question could be -- why do we only use Input-Hidden layer for embedding and why not Hidden-Last? It seems we can use both based on the type of task we are performing. For more details refer the paper -- Intrinsic analysis for dual word embedding space models
References
[1] Efficient Estimation of Word Representations in Vector Space
[2] Lil’Log — Learning word embedding
[3] Wevi — word embedding visual inspector
[4] Word2Vec Tutorial Part 2 - Negative Sampling